
Introducción
¿Alguna vez has necesitado probar un filtro de jq o una expresión de awk sin tener acceso a una terminal? ¿No? Vaya, no esperaba esa respuesta, pero aun así continúo. Ya que quizás querías mostrarle a alguien cómo funciona sed sin pedirle que instale nada. Bueno, pues esa fricción me llevó a construir FlintBox: un laboratorio self-hosted, accesible desde el navegador, que te permite probar herramientas de texto como jq, awk, sed, grep y cut de manera fácil y segura.

La idea es simple: una interfaz web donde puedes escribir tus parámetros, pegar datos de entrada (o hacer fetch desde una URL), ejecutar la herramienta y ver el resultado real. El binario real, en un contenedor aislado, con salida real.
Demo en vivo → flintbox.neanderhub.com
Por Qué el Binario Real Importa
A esto me refiero a que perfectamente pude haber creado algo "simulado" o "controlado", pero considero que eso le quita diversión y utilidad al laboratorio. Cuando aprendes jq o awk, lo que quieres entender es cómo se comporta la herramienta de verdad — no una aproximación. Una simulación en JavaScript puede funcionar para casos básicos, pero el comportamiento real diverge en todo lo que importa:
- Las versiones específicas de
jqtienen diferencias de semántica que afectan filtros avanzados - Los flags encadenados de
grep(-E,-v,-ojuntos) producen resultados que un mock no puede predecir fielmente awkcon múltiples patrones, bloquesBEGIN/ENDy variables externas requiere el intérprete real para dar la salida correcta- El comportamiento con entradas vacías, caracteres especiales o encodings inesperados solo lo reproduce el binario real
Si el objetivo del laboratorio es aprender y probar herramientas reales, simularlas derrota el propósito. FlintBox ejecuta los binarios en un contenedor aislado: lo que ves en pantalla es exactamente lo que verías en tu terminal.
Las Herramientas Disponibles
Cada herramienta tiene su panel dedicado con un ejemplo de inicio. Aquí un recorrido rápido por lo que puedes hacer.
jq — Filtrar y transformar JSON
Filtro: .[] | .name
Input:
[{"name":"Alice","age":30},{"name":"Bob","age":25}]
Output:
"Alice"
"Bob"
jq es la herramienta por defecto cuando trabajas con APIs REST. Puedes encadenar filtros, seleccionar campos, aplanar estructuras anidadas, transformar arrays, y mucho más. FlintBox corre jq 1.8 y tienes acceso al panel de ayuda con flags y ejemplos de filtros directamente en la interfaz.
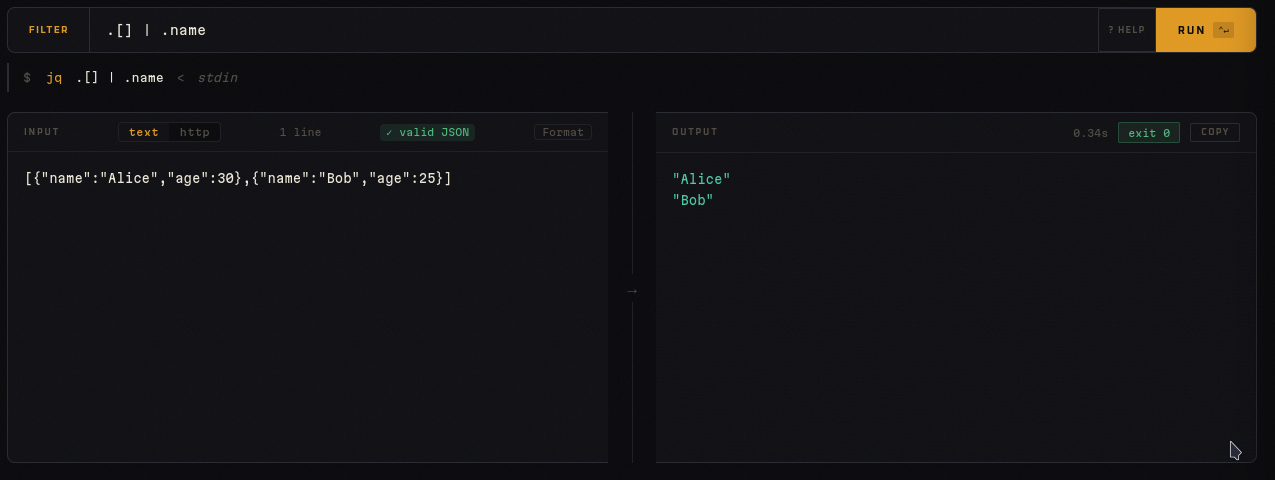
grep — Buscar patrones en texto
Flags: -i root
Input:
admin:x:1000:1000::/home/admin:/bin/bash
root:x:0:0:root:/root:/bin/sh
guest:x:1001:1001::/home/guest:/bin/sh
Output:
root:x:0:0:root:/root:/bin/sh
Útil para filtrar logs, extraer líneas que coinciden con un patrón, o validar expresiones regulares. Soporta -E para regex extendida, -v para invertir el match, -o para extraer solo la parte que coincide, y contexto con -A, -B, -C.
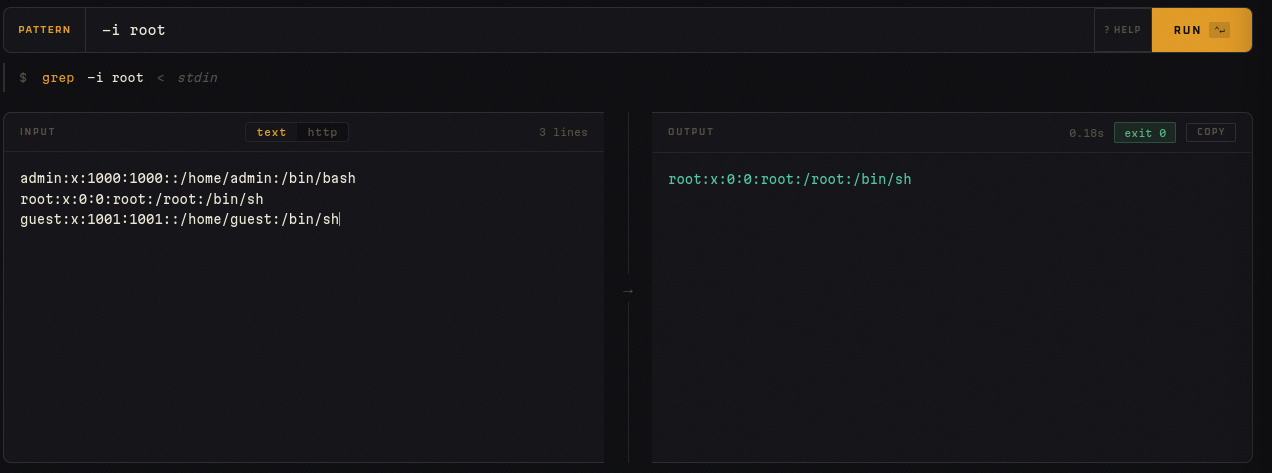
sed — Transformar líneas de texto
Expresión: s/error/WARN/g
Input:
2024-01-01 error: db timeout
2024-01-02 error: conn refused
2024-01-03 info: ok
Output:
2024-01-01 WARN: db timeout
2024-01-02 WARN: conn refused
2024-01-03 info: ok
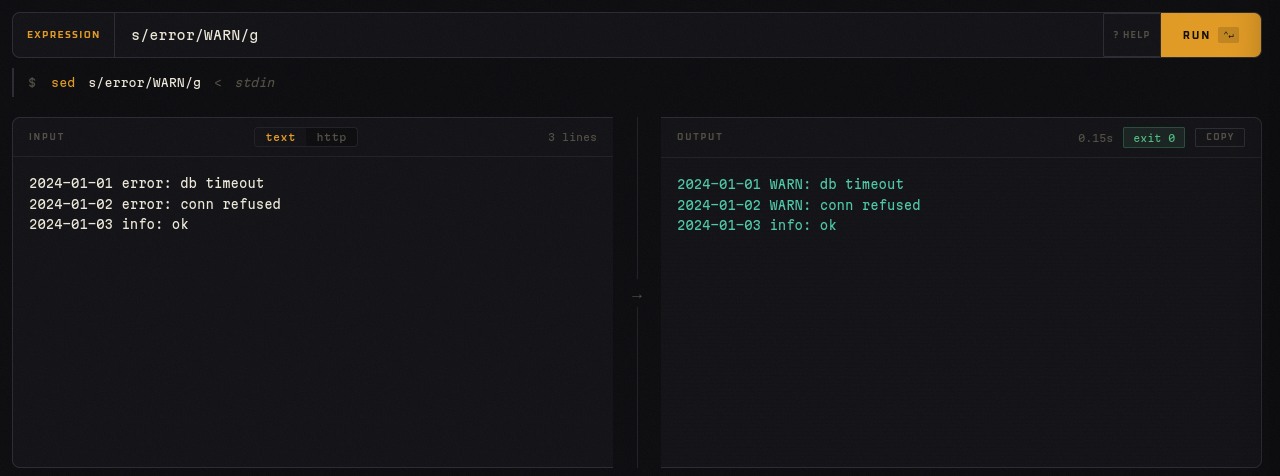
Ideal para reemplazos en logs, limpiar outputs de herramientas, o preparar datos antes de pasarlos a otro comando.
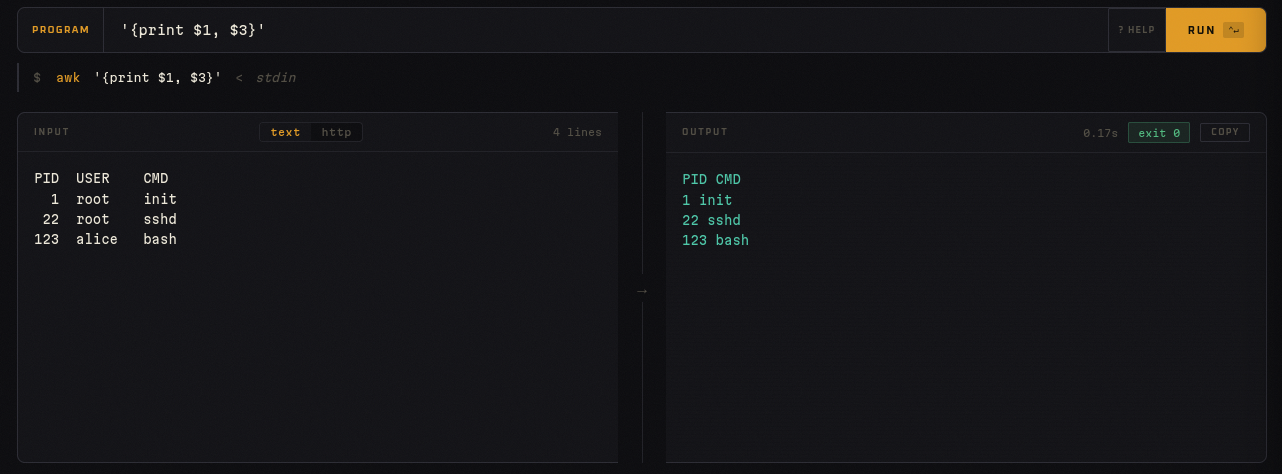
awk — Procesar texto estructurado por columnas
Programa: {print $1, $3}
Input:
PID USER CMD
1 root init
22 root sshd
123 alice bash
Output:
PID CMD
1 init
22 sshd
123 bash
awk brilla cuando los datos tienen estructura de columnas. Puedes definir separadores, sumar columnas, filtrar por condiciones, y usar bloques BEGIN/END para inicialización y resumen.
cut — Extraer campos de texto delimitado
Opciones: -d, -f1,3
Input:
apple,red,10
banana,yellow,5
kiwi,green,8
Output:
apple,10
banana,5
kiwi,8
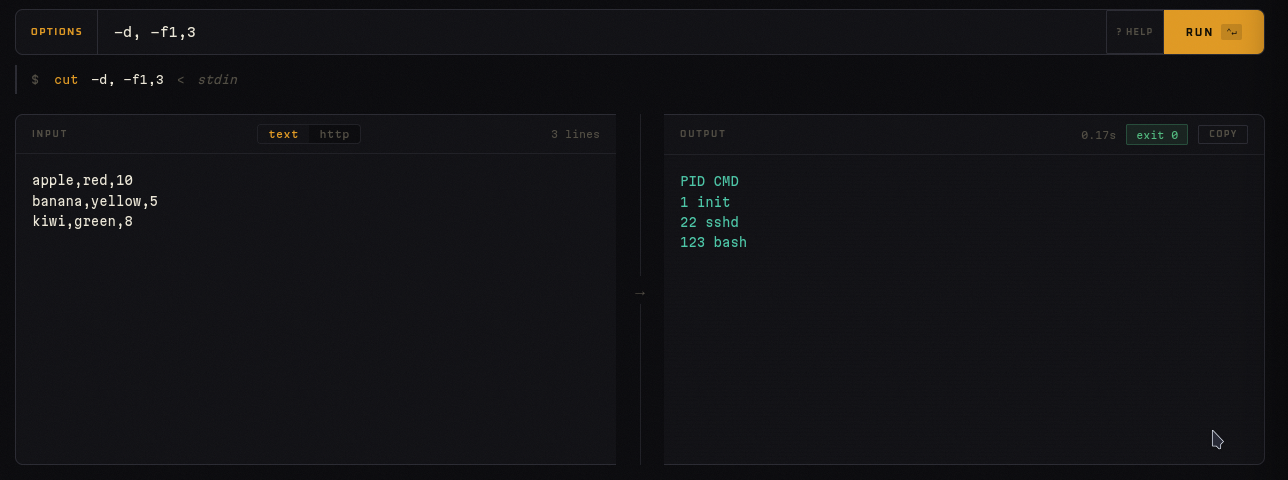
La herramienta más simple del grupo, pero indispensable para trabajar con CSV, TSV, o cualquier formato con delimitador fijo.
Input HTTP: Datos Reales de APIs
La verdad me daba mucha flojera tener que estar haciendo la petición a la api y copiar/pegar la salida en FlintBox así que una de las funcionalidades que más uso es el input HTTP. Basta con apuntar a una API y usar su respuesta directamente como stdin de la herramienta.
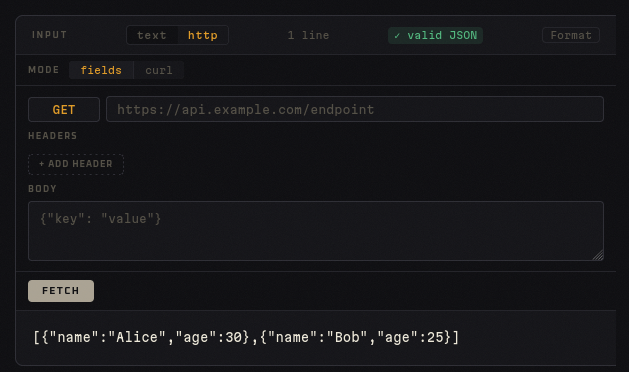
Hay dos modos:
Modo campos — formulario con método, URL, headers y body:
GET https://api.example.com/users
Accept: application/json
Modo curl — pega directamente el comando curl que ya tienes:
curl -H "Authorization: Bearer token123" \
-H "Accept: application/json" \
https://api.example.com/data
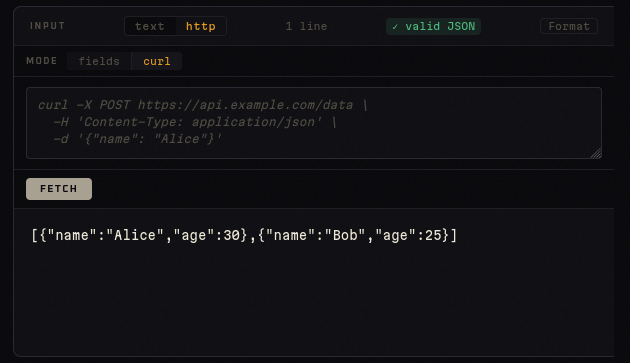
El parser de curl maneja continuaciones de línea (\), strings con comillas, y más de 20 flags (-X, -H, -d, --json, -L, -s, etc.). Al pulsar Run, el fetch ocurre automáticamente antes de ejecutar la herramienta.
Esto convierte FlintBox en algo muy práctico: apuntas a una API real, filtras con jq, extraes campos con awk, y ves el resultado limpio en segundos.
Desplegarlo
Para hacer sentido al título de "laboratorio selfhosted", obviamente necesitas poder desplegarlo tú mismo. FlintBox está construido con Docker Compose, así que el proceso es sencillo:
git clone https://github.com/4drian0rtiz/flintbox
cd flintbox
docker compose up --build -d
Abre http://localhost:3000 y tienes el laboratorio funcionando.
Conclusión
FlintBox nació de una necesidad real: un lugar donde probar jq, awk, sed y compañía sin fricción, con datos reales de APIs, sin instalar nada localmente. El binario real, en un contenedor aislado, con salida real.
No lo mencioné antes porque los que me conocen saben que siempre me doy un tiro con los nombres, y siempre termino con un juego de palabras rebuscadísimo. El nombre viene del pedernal — la herramienta primitiva más poderosa que existió. Herramientas primitivas, pero letales cuando sabes usarlas.
Desde La Cueva del NeanderTech te invito a desplegarlo, probarlo con tus propios datos y proponer nuevas tools. El código está disponible y las PRs son bienvenidas.
"Las herramientas más simples son las más poderosas — solo hay que saber dónde golpear."
